

Evolving packet processing by a factor of 1000
Part III: IP routing: packet processing silicon
Nokia’s FP5 IP router chipset has been a design four years in the making, the latest iteration of a two-decades-old packet processing architecture.
The 3-device FP5 chipset is implemented using a 7nm CMOS process. The design uses 2.5D stacked memory and is the first packet processor with 112 gigabit-per-second (Gbps) serialiser-deserialiser (serdes) interfaces. Also included are line-rate hardware encryption engines on the device’s ports.
 Ken Kutzler
Ken Kutzler
What hasn’t been revealed are such metrics as the chipset's power consumption, dimensions and transistor count.
Ken Kutzler, vice president of IP routing hardware at Nokia IP Networks Division, says comparing transistor counts of chips is like comparing software code: one programmer may write 10,000 lines while another may write 100 lines yet both may execute the same algorithm.
“It’s not always the biggest and baddest chip in the world that compares well,” says Kutzler.
GPU-CPU union
Kutzler says the FP5 can be characterised as combining the attributes of a graphics processing unit (GPU) with a general-purpose processor (CPU).
A GPU must deal with massive amounts of data - pixels - flowing through the device. “It’s a data flow model and that is what a packet processor has to do,” he says. A CPU, in contrast, processes data in blocks. A lot of the data processing involves moving data.
“You don't want to spend all that time with the processor moving data around, you want the data to move and the processing acting upon it,” says Kutzler. This is what the FP5 does: processes data as it flows.
“Our device has to be like a GPU in how data moves and like a CPU in that it has to be general-purpose,” he says. By general purpose, Nokia means having a programmable packet-processing pipeline rather than predefined hardware accelerator blocks.
“For service providers, the amount of features are pretty intense and they are ever-changing,” says Kutzler. “We have tended to forgo specialised engines that presuppose how something is parsed.”
Instead, the FP5 uses a command-level approach that ensures flexibility when implementing features.
 Source: Nokia, Gazettabyte
Source: Nokia, Gazettabyte
Programmable pipelines
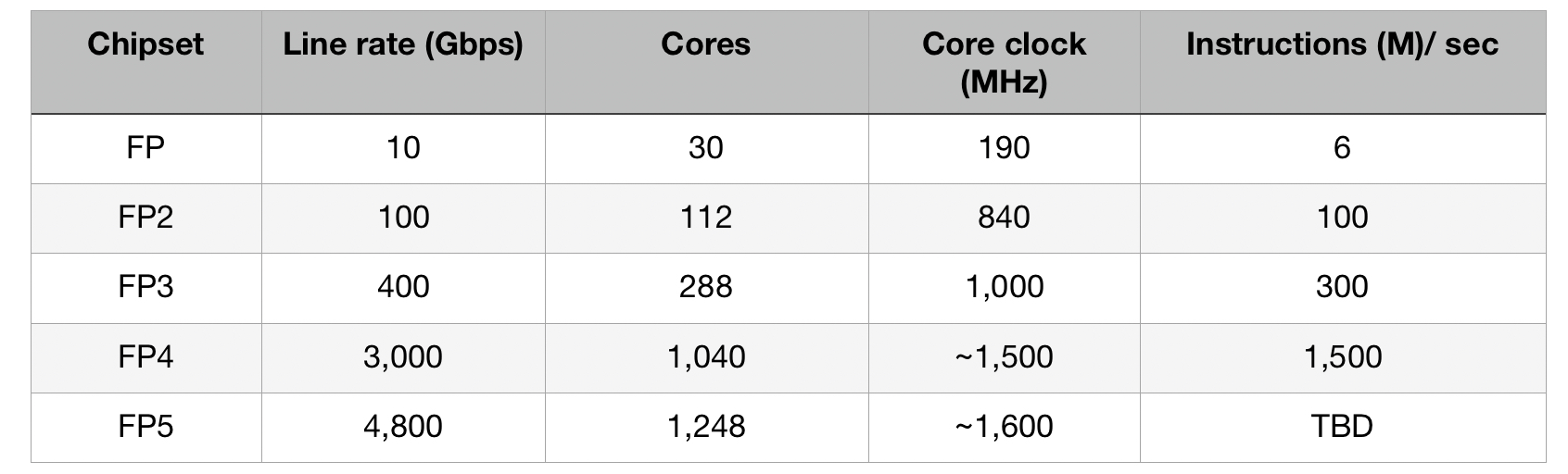
As implied by the name, the FP5 is the fifth-generation implementation of what started in 2003 as Alcatel’s FP packet processor. The FP had a 10Gbps line rate and used 30 packet-processing cores that ran microcode, each core being clocked at 190MHz.
The Alcatel-Lucent FP2 followed in 2007. The 100Gbps FP2 nearly quadrupled both the cores (112) and their clock rate (840MHz) and the trend continued with the 400Gbps FP3 announced in 2011.
The FP3 has 288, 1GHz cores arranged in a 2D array: 32 rows by 9 columns. Each row acts as a packet-processing pipeline that can be partitioned to perform independent tasks. The columns perform table look-ups and each column can be assigned more than one task.
The FP3 continues to carry IP network traffic and have its features enhanced using software upgrades, highlighting the benefit of a programmable packet processing architecture, says Kutzler.
The chipsets are also backwards compatible; the FP5 can implement the FP3’s instruction set, for example, but it also includes newer instructions. In one clock cycle, multiple instructions can be executed in an FP5 core. The core also supports multi-threading that did not exist with the FP3 whereby several instruction threads are interleaved and processed in parallel.
Chipset partitioning
Kutzler stresses that Nokia sells platforms and solutions, not chips. What matters to Nokia is that the silicon meets its platform requirements.
“I don’t really care what the ASIC speed is because I’m not going to sell it,” says Kutzler. “I care what the board speeds want.” For FP5-enabled platforms, that is 14.4 terabits.
But some customers want 2.4-terabit and 4.8-terabit capacities so what is needed is a power-efficient cost-effective solution across designs.
Partitioning the chipset functionality is reconsidered with each generation of design. “We will move things where it makes the most sense when designing our entire solution,” says Kutzler.
The 16nm CMOS 3Tbps FP4 chipset comprises a packet processor (p-chip) and the traffic manager (q-chip) as well as what was then a new chip, the e-chip. A media access controller (MAC), the e-chip parcels data from the router’s client-side pluggable optical modules for the packet processor.
However, Nokia combined the s-chip and t-chip withe FP4; the s-chip is a switch IC while the t-chip interfaces to the router’s fabric.
With the 7nm CMOS FP5, the p-chip and q-chip have finally been combined along with the t-chip.
Kutzler says the p- and q-chips could have been combined with earlier generation designs. But given the die cost (yield), it was deemed better to keep them separate. This also has system advantages: some FP3-based systems were configured using a combination of two p-chips and one q-chip.
“The p-chip is malleable; you can put it serially or in parallel,” says Kutzler. The compiler is told how the design is set up and the microcode is compiled accordingly.
The latest partitioning means the FP5 is a three-device chipset: the main chip (the packet processor, traffic manager and fabric interface), s-chip and the e-chip.
Terabit scale
The FP4 required a significant redesign for the architecture to continue to scale that took six years rather than its typical four-year design cycle.
“These were low-level changes, it [the FP4] still runs the same microcode but enhanced in such a way that the architecture can evolve,” says Kutzler.
The FP4 uses 1,040 cores, each enhanced to execute two instructions per clock cycle. The die-shrink allowed the cores to be clocked at 1.5GHz and hyper-threading was added, as mentioned. The FP4 also adopted 56Gbps serdes technology from Broadcom.
“When we talked about the FP4, we said it is setting this up for FP5 and that the FP5 would be coming much faster,” says Kutzler.
The FP5 increases the core count to 1,248 and doubles the serdes speed to 112Gbps.
“Serdes consume a considerable amount of power,” says Kutzler. Yet doubling the serdes speed saves power overall; a 112Gbps serdes consumes more power than a 56Gbps one but much less than twice the power.
Equally, putting two devices (the p-chip and q-chip) into one chip saves power otherwise required for chip-to-chip communications. Power is also saved when certain device features are not in use.
Nokia claims the FP5 designs consumes a quarter of the power of the FP4 ones when measured in Watts-per-gigabit (0.1W/gigabit compared to 0.4W/gigabit).
The 0.1W/gigabit is with the chipset’s features turned on including the encryption engines. “If a limited feature set is required, our expected power numbers will be below the full featured typical power consumption number,” says Jeff Jakab, Nokia’s director of IP routing hardware.
Memory
One issue IP router chip designers face is that the line rates of their chips are rising far faster than memory access speeds.
There are two memory types used for routing, each with its own requirements, says Nokia.
The first memory type is used for counters and table look-ups while the second buffers packets.
For counters/ look-ups what is needed is very high-speed memory that supports 32-bit and 64-bit reads and writes. In contrast, buffering requires much larger memories; the packet blocks are much larger requiring bigger reads and writes but they are not as simultaneous, says Kutzler.
Nokia developed its own ‘smart memory’ for the FP4 that is command-line driven. This means that a command can be used to perform a task that otherwise would require multiple memory accesses, thereby adding much-needed parallelism.
Four such smart memory dies are included in the FP4’s p-chip while for buffering, four high-bandwidth memory (HBM) blocks, each comprising stacked memory die, are part of the q-chip.
The FP5 integrates the smart memory on-chip, freeing up room for the latest HBM2e technology. “This allows us to get the speeds we need,” says Kutzler. “So when we say we have a 14.4-terabit card, it allows true QoS (quality of service) on every packet.”
“All chipsets released prior to the FP5 make use of HBM2 and are constrained to a maximum of some 1.7 terabits of full-duplex bandwidth to buffer memory,” says Jakab.
The FP4's HBM2 buffer memory supports a 1.5-terabit line rate whereas HBM2e can support a 2.4-terabit line rate.
“We are not aware of any other chipsets on the market that make use of HBM2e,” says Jakab, adding that these memory types generally cannot be substituted one for another without considerable redesign effort.
Nokia’s use of memory includes the FP5’s e-chip which plays a key role, as is now explained.
Board considerations
The e-chip is deliberately separated from the main chip as it performs packet pre-processing and packet pre-classification as well as pre-buffering in front of the packet processor.
“We use multiple e-chips in front of our packet processor to allow the faceplate of our card to expand in terms of port capabilities beyond the forwarding limit of our packet processor,” says Jakab.
 Jeff Jakab
Jeff Jakab
The e-chip delivers two advantages. It does away with pre-aggregation boxes in front of Nokia’s 7750 SR platform. Such 1 rack unit (1RU) pre-aggregation boxes are used to groom traffic into an edge router or smart aggregation platform.
A typical pre-aggregation box supports 32MB of buffering, says Jakab, whereas each e-chip uses nearly 20x that amount.
“It [using the e-chip] collapses the platforms in front, saving power and rack space while eliminating a layer from the network,” says Jakab.
In many IP edge or core applications, customers are not capacity restricted but port restricted. They run out of ports long before they run out of capacity because the majority of flows are all fractional.
A fractional flow is one that does not fill up the full bandwidth of an interface, for example 50 gigabits of traffic on a 100-gigabit interface or 7 gigabits of traffic on a 10 Gigabit Eternet interface.
This is the design use case of Nokia’s SR-1 router platform. “Aggregating a ton of fractional flows with many many connectivity option types is the ideal use case for smart aggregation," says Jakab.
The e-chip also helps Nokia's systems to benefit from what it calls intelligent aggregation which uses pre-classification and pre-buffering to guarantee the flows that matter most.
“It goes well beyond basic oversubscription because we pre-buffer and pre-classify to ensure that high priority traffic is always guaranteed,” says Jakab.
This is different from classic oversubscription where, when the given rate for a packet processor is exceeded, the next packet is by default discarded, irrespective of QoS, says Jakab.
“It means we can flexibly offer more ports on the faceplate of a card to satisfy increasing port requirements without fear of indiscriminate packet drops,” he says.
Nokia points out that its FP5 line cards expand capacity by 3x.
Its 4.8Tbps expandable media adaptor (XMA) card supports 12 terabit of intelligent aggregation by using four FP4 chipsets. Its latest XMA is 14.4Tbps, supports 19.2Tbps of IA, and uses six FP5 chipsets.
What next
Extrapolating four years hence to 2025, the FP6 packet processor will likely be a 5nm or 3nm CMOS design with a packet-processing capacity of some 10Tbps, a 1000x improvement on the first FP.
Kutzler stresses that the speed of the device is less important than meeting its IP system requirements for the decade that will follow. It is these requirements that will shape the FP6 design.
Kutzler did share one thing about the FP6: it will use 224Gbps serdes.
 Post a Comment
Post a Comment
Reader Comments