

Broadcoms taps AI to improve switch chip traffic analysis
Broadcom's Trident 5-X12 networking chip is the company's first to add an artificial intelligence (AI) inferencing engine.
 The latest Trident, Tomahawk, and Jericho devices. Source: Broadcom.
The latest Trident, Tomahawk, and Jericho devices. Source: Broadcom.
Data centre operators can use their network traffic to train the chip's neural network. The Trident 5's inference engine, dubbed the Networking General-purpose Neural-network Traffic-analyzer or NetGNT, is loaded with the resulting trained model to classify traffic and detect security threats.
"It is the first time we have put a neural network focused on traffic analysis into a chip," says Robin Grindley, principal product line manager with Broadcom's Core Switching Group.
Adding an inference engine shows how AI can complement traditional computation, in this case, packet processing.
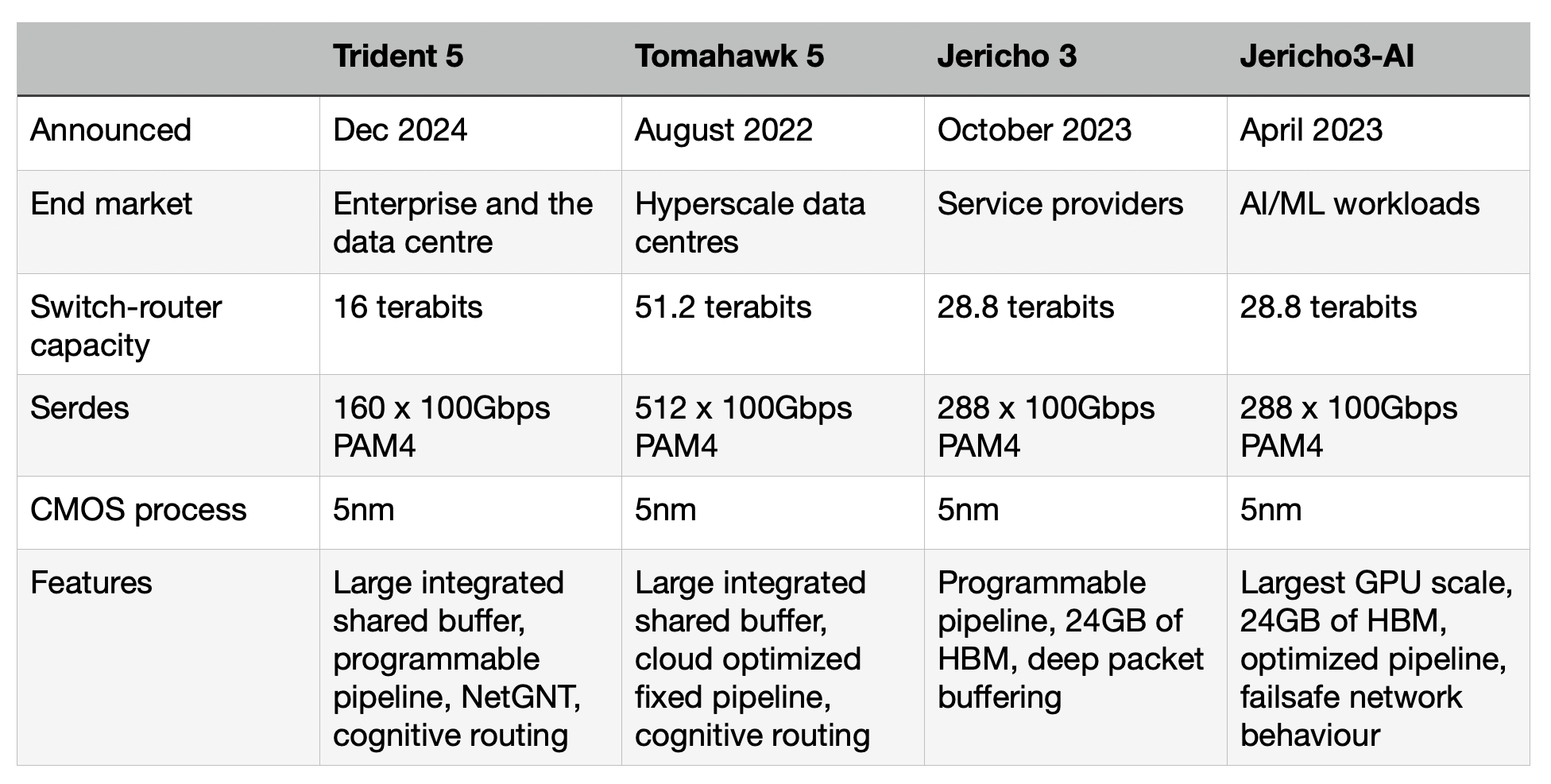
Trident family
Trident is one of Broadcom's main three lines of networking and switch chips, the Jericho and Tomahawk being the other two.
Service providers favour the Jericho family for high-end IP routing applications. The Ethernet switch router chip's features include a programmable pipeline and off-chip store for large traffic buffering and look-up tables.
The latest Jericho 3, the 28.8 terabits-per-sec (Tbps) Jericho 3, was announced in September. Broadcom launched the first family device, the Jericho3-AI, earlier this year; a chip tailored for AI networking requirements.
In contrast, Broadcom's Tomahawk Ethernet network switch family addresses the data centre operators' needs. The Tomahawk has a relatively simple fixed packet-processing pipeline to deliver the highest switching capacity. The Tomahawk 5 has a capacity of 51.2 terabits and includes 512, 100-gigabit PAM4 serialiser-deserializer (serdes).
"The big hyperscalers want maximum bandwidth and maximum radix [switches]," says Grindley. "The hyperscalers have a pretty simple fabric network and do everything else themselves."
The third family, the Trident Ethernet switch chips, is popular for enterprise applications. Like the Jericho, the Trident has a programmable pipeline to address enterprise networking tasks such as Virtual Extensible LAN (VXLAN), tunnelling protocols, and segment routing (SRv6).
The speeds and timelines of the various Tomahawk and Trident chips are shown in the chart.
 Timelines of the Tomahawk and Trident devices. Source: Broadcom.
Timelines of the Tomahawk and Trident devices. Source: Broadcom.
Trident 5-X12
The Trident 5-X12 is implemented using a 5nm CMOS process and has a capacity of 16 terabits. The chip's input-output includes 160, 100-gigabit PAM4 serdes. These are the serdes that Broadcom introduced with the Tomahawk 5.
The first chip of each new generation of Trident usually has the highest capacity and is followed by lower-capacity devices tailored to particular markets.
 Source: Broadcom.
Source: Broadcom.
Trident 5 is aimed at top-of-rack switch applications. Typically, 24 or 48 ports of the top-of-rack switch are used for downlinks to connect to servers, while 4 or 8 are used for higher-capacity uplinks (see diagram).
The Trident 5 can support 48 ports of 200 gigabits for the downlinks and eight 800 gigabit for the uplinks. To support 800-gigabit interfaces, the chip uses eight 100-gigabit serdes and an one-chip 800-gigabit media access controller (MAC). Other top-of-rack switch configurations are shown in the diagram.
Currently, 400-gigabit network interface cards are used for demanding applications such as machine learning. Trident5 is also ready to transition to 800-gigabit network interface cards.
Another Tomahawk feature the Trident 5 has adopted is cognitive routing, a collection of congestion management techniques for demanding machine-learning workloads.
One of the techniques is global load balancing. Previous Trident devices supported dynamic load balancing, where the hardware could see the congested port and adapt in real-time. However, such a technique gives no insight into what happens further along the flow path. "If I knew that, downstream, somebody else was congested, then I could make a smarter decision," says Grindley. Global load balancing does just this. It sends notification to the routing chips upstream that there is congestion so they can all work together.
Another cognitive routing feature is drop congestion notification. Here, packets dropped due to congestion are captured such that what is sent is only their header data and where the packet was dropped. This mechanism improves flow completion times compared to normal packet loss, which is costly for machine-learning workloads.
Trident 5, like its predecessor, Trident 4, has a heterogeneous pipeline of tile types. The tiles contain static random-access memory (SRAM), ternary content-addressable memory (TCAM) or arithmetic logic units. The tiles allow multiple look-ups or actions in parallel at each stage in the pipeline.
 Trident 5 including the NetGNT inference engine. Source: Broadcom.
Trident 5 including the NetGNT inference engine. Source: Broadcom.
Broadcom has a compiler that maps high-level packet-processing functions to its pipeline in the NPL programming language. The latency through the device stays constant, however the packet processing is changed, says Grindley.
Trident 5's NetGNT inference engine is a new pipeline resource for higher-level traffic patterns. "NexGNT looks at things not at a packet-by-packet level, but across time and the overall packet flow through the network," says Grindley.
The NetGNT
Until now system architects and network operation centre staff have defined a set of static rules written in software to uncover and treat suspicious packet flows. "A pre-coded set of rules is limited in its ability to catch higher-level traffic patterns," says Grindley.
When Broadcom started the Trident 5 design, its engineers thought a neural network approach could be used. "We knew it would be useful if you had something that looked at a higher level, and we knew neural networks could do this kind of task," says Grindley.
The neural network sits alongside the existing traffic analysis logic. Information such as packet headers, or data already monitored and generated by the pipeline, can be fed to the neural network to assess the traffic patterns.
"It sits there and looks for high-level patterns such as the start of a denial of service attack" says Grindley.
Training
The neural network is trained using supervised learning. A human expert must create the required training data and train the model using supervised learning. The result is a set of weights loaded onto the Trident 5's neural network.
 Source: Broadcom.
Source: Broadcom.
When the neural network is triggered, i.e. when it identifies a pattern of interest, the Trident 5 must decide what it should do. The chip can drop the packets or change the quality of service (QoS). The device can also drop a packet while creating a mirror packet containing headers and metadata. This can then be sent to a central analyser at the network operations centre to perform higher-level management algorithms.
Performance
The Trident 5 chip is now sampling. Broadcom says there is no performance data as end customers are still to train and run live traffic through the Trident 5's inference engine.
"What it can do for them depends on getting good data and then running the training," says Grindley. "Nobody has done this yet."
Will the inference engine be used in other Broadcom networking chips?
"It depends on the market," says Grindley. "We can replicate it, just like taking IP from the Tomahawk where appropriate."
 Post a Comment
Post a Comment
Reader Comments