Broadcom’s Jericho silicon has taken an exciting turn.
 Oozie Parizer
Oozie Parizer
The Jericho devices are used for edge and core routers.
But the first chip of Broadcom’s next-generation Jericho is aimed at artificial intelligence (AI); another indicator, if one is needed, of AI’s predominance.
Dubbed the Jericho3-AI, the device networks AI accelerator chips that run massive machine-learning workloads.
AI supercomputers
AI workloads continue to grow at a remarkable rate.
The most common accelerator chip used to tackle such demanding computations is the graphics processor unit (GPU).
GPUs are expensive, so scaling them efficiently is critical, especially when AI workloads can take days to complete.
“For AI, the network is the bottleneck,” says Oozie Parizer, (pictured) senior director of product management, core switching group at Broadcom.
Squeezing more out of the network equates to shorter workload completion times.
“This is everything for the hyperscalers,” says Parizer. “How quickly can they finish the job.”
Broadcom shares a chart from Meta (below) showing how much of the run time for its four AI recommender workloads is spent on networking, moving the data between the GPUs.
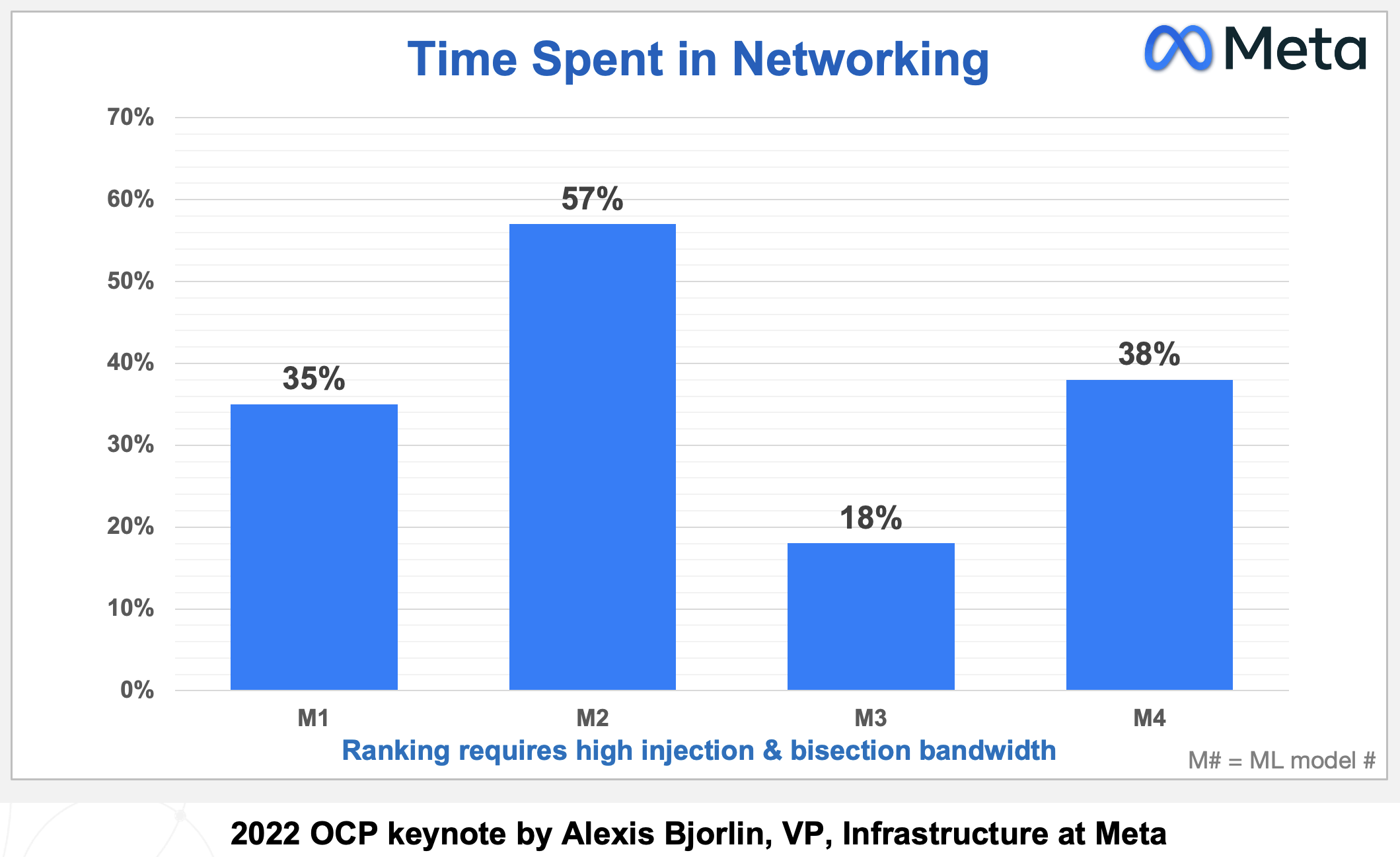 Time spent on network for four recommender workloads. Source: Meta
Time spent on network for four recommender workloads. Source: Meta
In the worse case, networking accounts for three fifths (57 per cent) of the time during which the GPUs are idle, waiting for data.
Scaling
Parizer highlights two trends driving networking for AI supercomputers.
One is the GPU’s growing input-output (I/O), causing a doubling of the interface speed of network interface cards (NICs). The NIC links the GPU to the top-of-rack switch.
The NIC interface speeds have progressed from 100 to 200 to now 400 gigabits and soon 800 gigabits, with 1.6 terabits to follow.
The second trend is the amount of GPUs used for an AI cluster.
The largest cluster sizes have used 64 or 256 GPUs, limiting the networking needs. But now machine-learning tasks require clusters of 1,000 and 2,000 GPUs up to 16,000 and even 32,000.
Meta’s Research SuperCluster (RSC), one of the largest AI supercomputers, uses 16,000 Nvidia A100 GPUs: 2,000 Nvidia DGX A100 systems each with eight A100 GPUs. The RSC also uses 200-gigabit NICs.
“The number of GPUs participating in an all-to-all exchange [of data] is growing super fast,” says Parizer.
The Jericho3-AI is used in the top-of-rack switch that connects a rack's GPUs to other racks in the cluster.
The Jericho3-AI enables clusters of up to 32,000 GPUs, each served with an 800-gigabit link.
An AI supercomputer can used all its GPUs to tackle one large training job or split the GPUs into pools running AI workloads concurrently.
Either way, the cluster’s network must be ‘flat’, with all the GPU-to-GPU communications having the same latency.
Because the GPUs exchange machine-learning training data in an all-to-all manner, only when the last GPU receives its data can the computation move onto the next stage.
“The primary benefit of Jericho3-AI versus traditional Ethernet is predictable tail latency,” says Bob Wheeler, principal analyst at Wheeler’s Network. “This metric is very important for AI training, as it determines job-completion time.”
Data spraying
“We realised in the last year that the premium traffic capabilities of the Jericho solution are a perfect fit for AI,” says Parizer.
The Jericho3-AI helps maximise GPU processing performance by using the full network capacity while traffic routing mechanisms help nip congestion in the bud.
The Jericho also adapts the network after a faulty link occurs. Such adaptation must avoid heavy packet loss otherwise the workload must be restarted, potentially losing days of work.
AI workloads use large packet streams known as ‘elephant’ flows. Such flows tie up their assigned networking path, causing congestion when another flow also needs that path.
“If traffic follows the concept of assigned paths, there is no way you get close to 100 per cent network efficiency,” says Parizer.
The Jericho3-AI, used in a top-of-rack switch, has a different approach.
Of the device’s 28.8 terabits of capacity, half connects the rack’s GPUs’ NICs and a half to the ‘fabric’ that links the rack’s GPUs to all the other cluster’s GPUs.
Broadcom uses the 14.4-terabit fabric link as one huge logical pipe over which traffic is evenly spread. Each destination Jericho3-AI top-of-rack switch then reassembles the ‘sprayed’ traffic.
“From the GPU’s perspective, it is unaware that we are spraying the data,” says Parizer.
Receiver-based flow control
Spraying may ensure full use of the network’s capacity, but congestion can still occur. The sprayed traffic may be spread across the fabric to all the spine switches, but for short periods, several GPUs may send data to the same GPU, known as incast (see diagram).
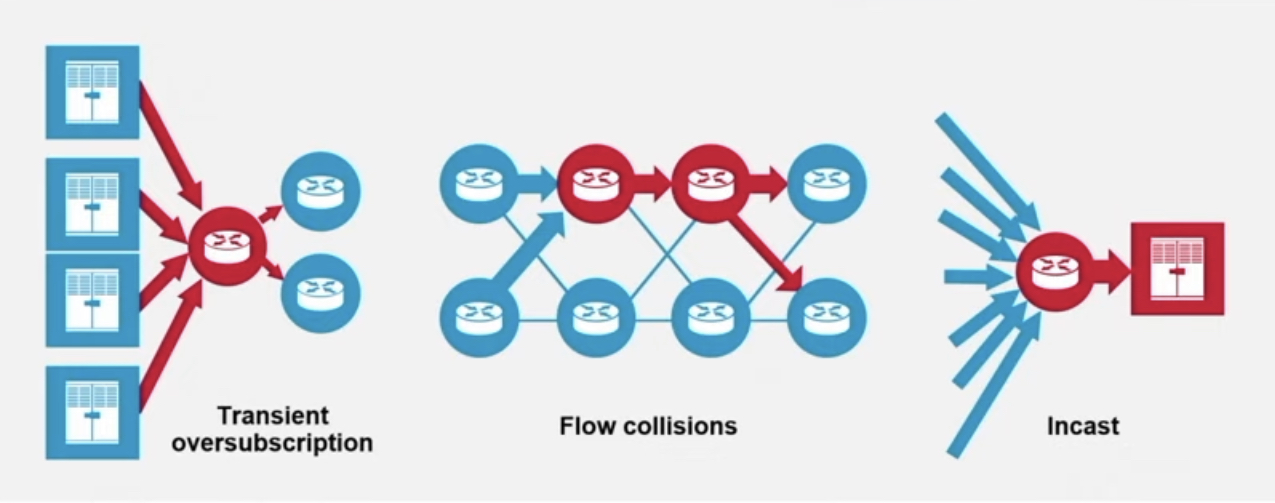 The networking challenges tackled by Jericho3-AI. Source: Broadcom
The networking challenges tackled by Jericho3-AI. Source: Broadcom
The Jericho copes with this many-to-one GPU traffic using receiver-based flow control.
Traffic does not leave the receiving Jericho chip just because it has arrived, says Parizer. Instead, the receiving Jericho tells the GPUs with traffic to send and schedules part of the traffic from each.
“Traffic ends up queueing nearer the sender GPUs, notifying each of them to send a little bit now, and now,” says Parizer, who stresses this many-to-one condition is temporary.
Ethernet flow control is used when Jericho chip senses that too much traffic is being sent.
“There is a temporary stop in data transmission to avoid packet loss in network congestion,” says Parizer. “And it is only that GPU that needs to slow down; it doesn’t impact any adjacent GPUs.”
Fault control
At Optica’s Executive Forum event, held alongside the OFC show in March, Google discussed using a 6,000 tensor processor unit (TPU) accelerator system to run large language models.
One Google concern is scaling such clusters while ensuring overall reliability and availability, given the frailty of large-scale accelerator clusters.
“With a huge network having thousands of GPUs, there is a lot of fibre,” says Parizer. “And because it is not negligible, faults happen.”
New paths must be calculated when an optical link goes down in a network arrangement that using flows and assigned paths with significant traffic loss likely.
“With a job that has been running for days, significant packet loss means you must do a job restart,” says Parizer.
Broadcom’s solution, not based on flows and assigned paths, uses load balancing to send data over one less path overall.
Using the Jericho2C+, Broadcom has shown fault detection and recovery in microseconds such that the packet loss is low and no job restart is needed.
________________________________________________________________________
The Jericho portfolio of devices
Broadcom’s existing Jericho2 architecture combines an enhanced packet-processing pipeline with a central modular database and a vast memory holding look-up tables.
Look-up tables are used to determine how the packet is treated: where to send it, wrapping it in another packet (tunnel encapsulation), extracting it (tunnel termination), and access control lists (ACLs).
Different stages in the pipeline can access the central modular database, and the store can be split flexibly without changing the packet-processing code.
Jericho2 was the first family device with a 4.8 terabit capacity and 8 gigabytes of high bandwidth memory (HBM) for deep buffering.
The Jericho 2C followed, targeting the edge and service router market. Here, streams have lower bandwidth - 1 and 10 gigabits typically - but need better support in the form of queues, counters and metering, used for controlling packets and flows.
Pariser says the disaggregated OpenBNG initiative supported by Deutsche Telekom uses the Jericho 2C.
Broadcom followed with a third Jericho2 family device, the Jericho 2C+, which combines the attributes of Jericho2 and Jericho2C.
Jericho2C+ has 14.4 terabits of capacity and 144 100-gigabit interfaces, of which 7.2-terabit is network interfacing bandwidth and 7.2-terabit for the fabric interface.
“The Jericho2C+ is a device that can target everything,” says Pariser.
Applications include data centre interconnect, edge and core network routing, and even tiered switching in the data centre.
________________________________________________________________________
Hardware design
The Jericho3-AI, made up of tens of billions of transistors in a 5nm CMOS process, is now sampling.
Broadcom says it designed the chip to be cost-competitive for AI.
For example, the packet processing pipeline is simpler than the one used for core and edge routing Jericho.
“This also translates to lower latency which is something hyperscalers also care about,” says Parizer.
The cost and power savings from optimisations will be relatively minor, says Wheeler.
 The Jericho3-AI's main attributes. Source: Broadcom
The Jericho3-AI's main attributes. Source: Broadcom
Broadcom also highlights the electrical performance of the Jericho3-AI’s input-output serialiser-deserialiser (serdes) interfaces.
The serdes allows the Jericho3-AI to be used with 4m-reach copper cables linking the GPUs to the top-of-rack switch.
The serdes performance also enables linear-drive pluggables that dont have no digital signal processor (DSP) for retiming with the serdes driving the pluggable directly. Linear drive saves cost and power.
Broadcom’s Ram Valega, senior vice president and general manager of the core switching group, speaking at the Open Compute Project’s regional event held in Prague in April, said 32,000 GPU AI clusters cost around $1 billion, with 10 per cent being the network cost.
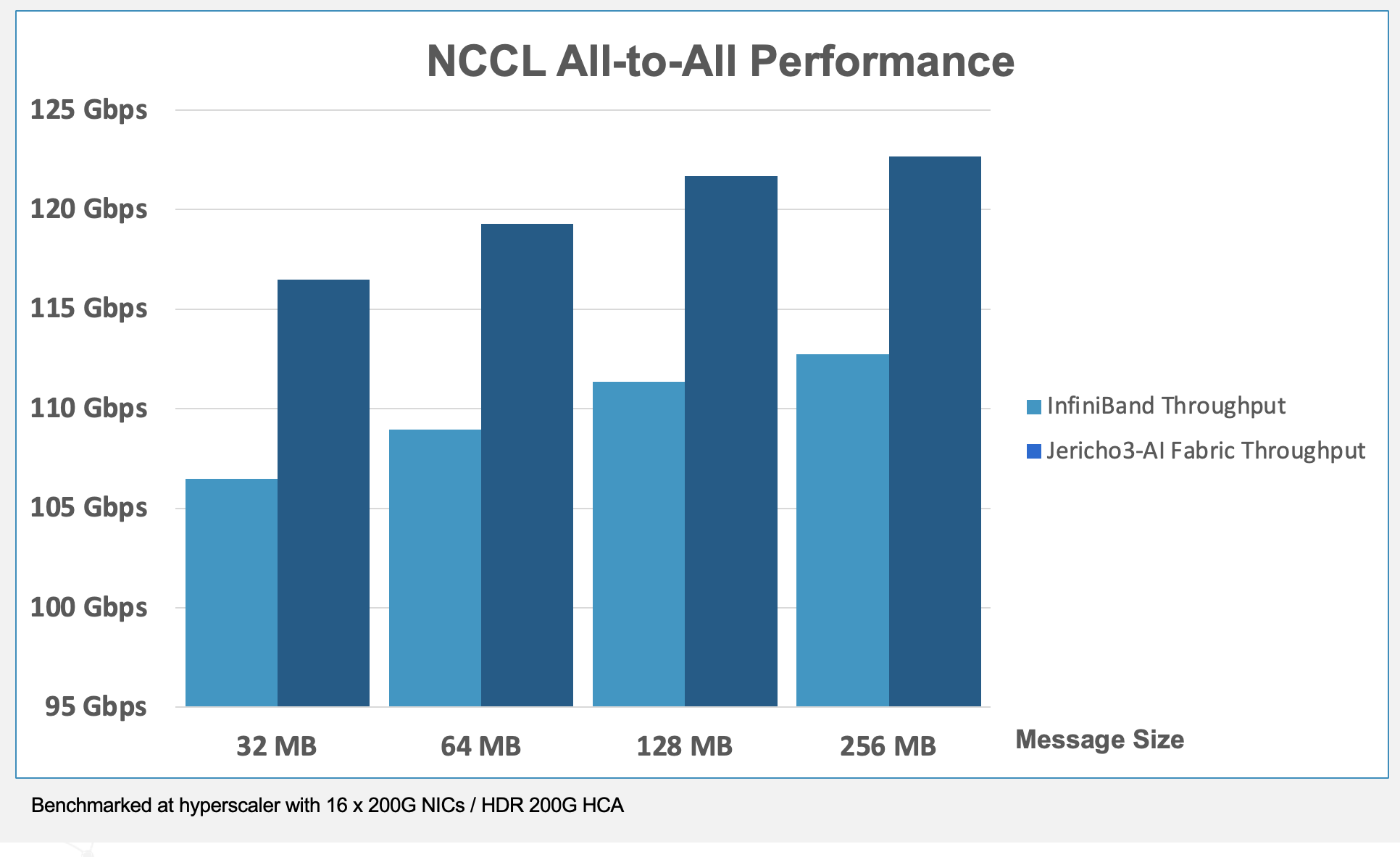 NCCL refers to the NVIDIA Collective Communications Library, a set of inter-GPU communication primitives that can be integrated into applications. Performance tests run over NCCL can be used to measure the performance of a workload. Source: Broadcom
NCCL refers to the NVIDIA Collective Communications Library, a set of inter-GPU communication primitives that can be integrated into applications. Performance tests run over NCCL can be used to measure the performance of a workload. Source: Broadcom
Valega showed Ethernet outperforms Infiniband by 10 per cent for a set of networking benchmarks (see diagram above).
“If I can make a $1 billion system ten per cent more efficient, the network pays for itself,” says Valega.
Wheeler says the comparison predates the recently announced NVLink Network, which will first appear in Nvidia’s DGX GH200 platform.
“It [NVLink Network] should deliver superior performance for training models that won’t fit on a single GPU, like large language models,” says Wheeler.