- Enfabrica’s accelerated compute fabric chip is designed to scale computing clusters comprising CPUs and specialist accelerator chips.
- The chip uses memory disaggregation and high-bandwidth networking for accelerator-based servers tackling artificial intelligence (AI) tasks.
 Rochan Sankar
Rochan Sankar
For over a decade, cloud players have packed their data centres with x86-based CPU servers linked using tiers of Ethernet switches.
“The reason why Ethernet networking has been at the core of the infrastructure is that it is incredibly resilient,” says Rochan Sankar, CEO and co-founder of Enfabrica.
But the rise of AI and machine learning is causing the traditional architecture to change.
What is required is a mix of processors: CPUs and accelerators. Accelerators are specialist processors such as graphics processing units (GPUs), programmable logic (FPGAs), and custom ASICs developed by the hyperscalers.
It is the accelerator chips, not the CPUs, that do the bulk of the processing. Accelerators also require vast data, creating challenging input-output (I/O) and memory requirements.
At Optica’s Executive Forum event, held alongside the OFC show in March, Ryohei Urata, director and principal engineer at Google, mentioned how Google uses two computing pods - comprising 6,000 TPU accelerators - to run its large language models.
A key concern for Google is scaling such clusters while ensuring their reliability and availability. It is critical that the system is available when running a large language model, says Urata,
“As an engineer, when you're putting stuff down, at least when you're first start to put it together, you think, okay, this is going to work perfectly,” says Urata. “This is a perfect design, you don't factor in failing gracefully, so that's a key lesson.”
Google’s concern highlights that accelerator-based clusters lack the reliability of data centre server-Ethernet networks.
Accelerated compute fabric
Start-up Enfabrica has developed a chip, dubbed the accelerated compute fabric, to scale computing clusters.
“The focus of Enfabrica is on how networking and fabric technologies have to evolve in the age of AI-driven computing,” says Sankar.
AI models are growing between 8x to 275x annually, placing enormous demands on a data centre’s computing and memory resources.
“Two hundred and seventy-five times are of the order of what the large language models are increasing by, 8x is more other models including [machine] vision; recommender models are somewhere in between,” says Sankar.
Another AI hardware driver is growing end-user demand; ChatGPT gained 100 million users in the first months after its launch.
Meeting demand involves cascading more accelerators but the I/O bandwidth connected to the compute is lagging. Moreover, that gap is growing.
Sankar includes memory bandwidth as part of the I/O issue and segments I/O scaling into two: connecting CPUs, GPUs, accelerators and memory in the server, and the I/O scaling over the network.
A computing architecture for AI must accommodate greater CPUs and accelerators yet tackle the I/O bottleneck.
“To scale, it requires disaggregation; otherwise, it becomes unsustainable and expensive, or it can’t scale enough to meet processing demands,” says Sankar
“Memory disaggregation represents the last step in server disaggregation, following storage and networking,” says Bob Wheeler, principal analyst at Wheeler’s Network.
Memory expansion through disaggregation has become more urgent as GPUs access larger memories for AI training, particularly for large language modules like ChatGPT, says Wheeler.
Rethinking data connectivity
In the data centre, servers in a rack are linked using a top-of-rack switch. The top-of-rack switch also connects to the higher-capacity leaf-spine Ethernet switching layers to link servers across the data centre.
Enfabrica proposes that the higher capacity Ethernet switch leaf layer talks directly to its accelerated compute fabric chip, removing the top-of-rack switch.
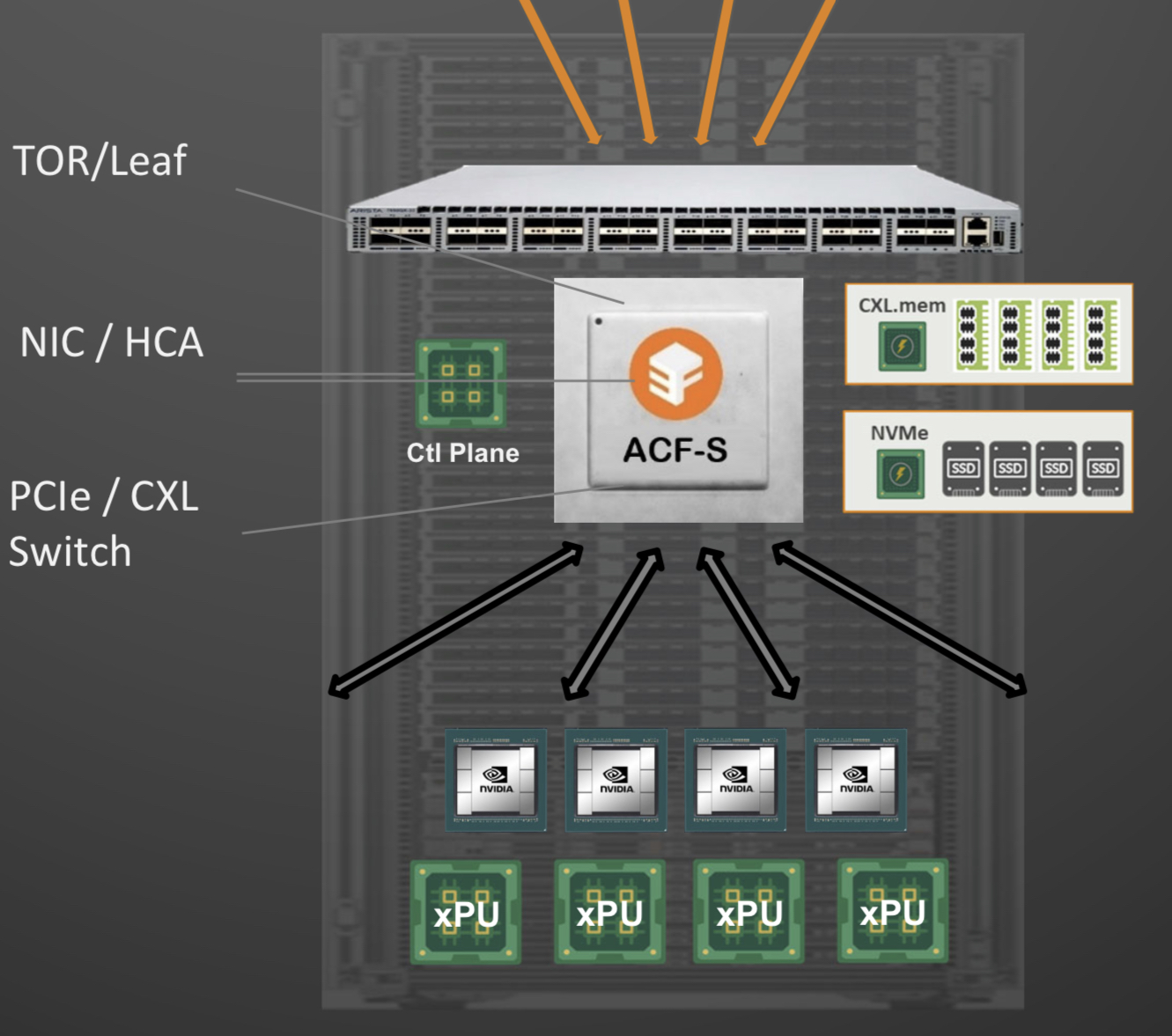 Source: Enfabrica.
Source: Enfabrica.
In turn, the accelerated compute fabric uses memory mapping to connect CPUs, accelerators, disaggregated memory pools using CXL, and disaggregated storage (see diagram above).
The memory can be a CPU’s DDR DRAM, a GPU’s high-bandwidth memory (HBM), a disaggregated compute express link (CXL) memory array, or storage.
“It [the accelerated compute fabric] connects to them over standard memory-mapped interfaces such as PCI Express (PCIe) or CXL,” says Sankar.
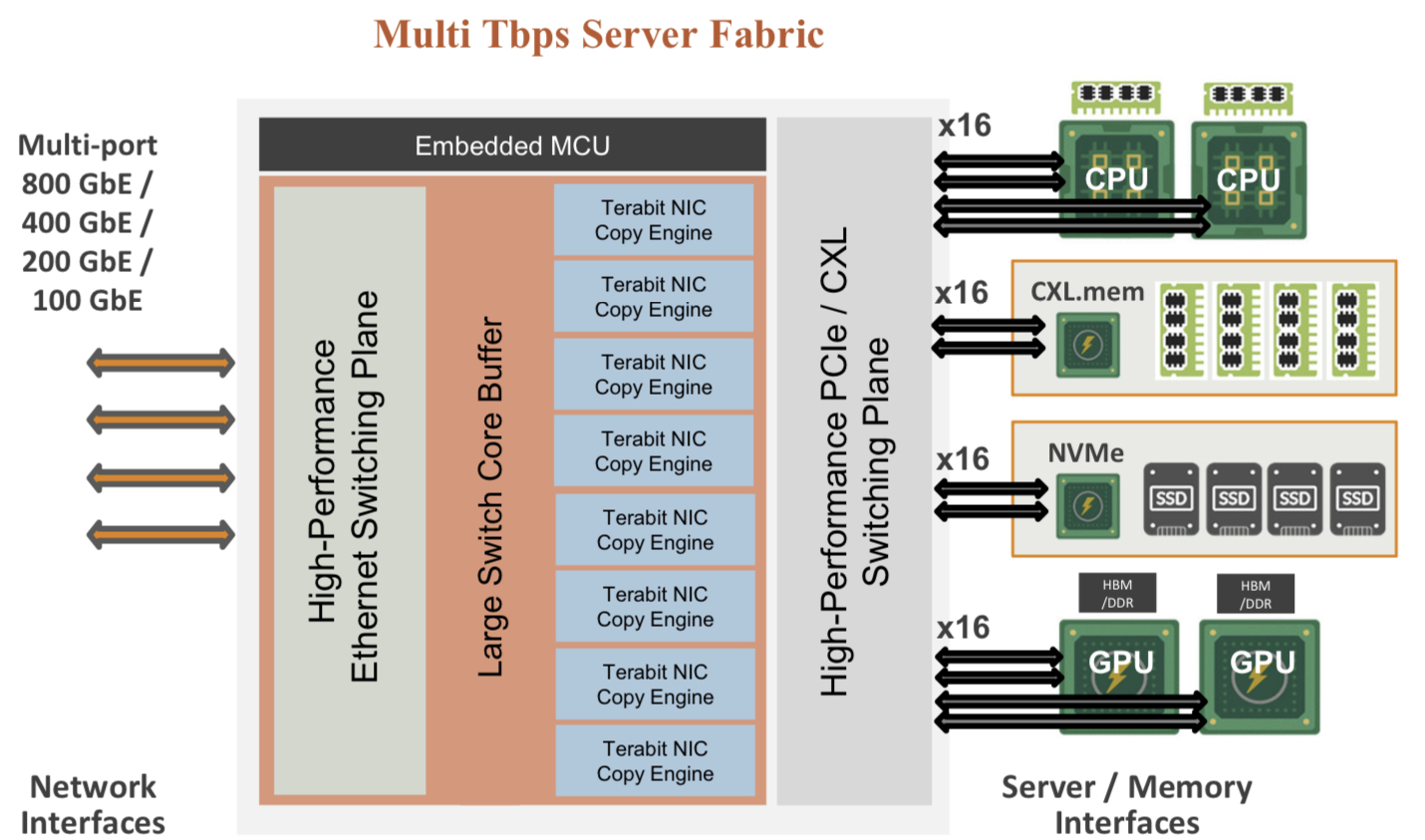 The functional blocks and interfaces of the accelerate compute fabric architecture. Source: Enfabrica
The functional blocks and interfaces of the accelerate compute fabric architecture. Source: Enfabrica
The chip uses ‘copy engines’ to move data to and from any processing element’s native memory. And by performing memory transfers in parallel, the chip is doing what until now has required PCIe switches, network interface cards (NICs), and top-of-rack switches.
The accelerated compute fabric also has 800-gigabit network interfaces so that, overall, the chip has terabits of bandwidth to move data across the network.
“CXL provides a standard way to decouple memories from CPUs, enabling DRAM disaggregation,” says Wheeler. “Enfabrica’s copy engines connect the GPUs to the pool of CXL memory. The network side, using RDMA (remote direct memory access), enables scaling beyond the limits of CXL.”
Sankar stresses that the accelerated compute fabric is much more than an integration exercise using an advanced 5nm CMOS process.
“If you were to integrate eight NICs, four PCIe switches and a top-of-rack switch, it would not fit into a single die,” says Sankar.
As for software, Enfabrica has designed its solution to fit in with how GPUs, CPUs and memory move data.
Significance
Sankar says the accelerated compute fabric IC will shorten job completion time because the scheduler is finer-grained and the chip can steer I/O to resources as required.
Computing clusters will also become larger using the IC’s high-density networking and CXL.
Wheeler says that CXL 3.x fabrics could provide the same capabilities as the accelerated compute fabric, but such advanced features won’t be available for years.
“History suggests some optional features included in the specifications will never gain adoption,” says Wheeler.
“The CXL/PCIe side of the [accelerated compute fabric] chip enables memory disaggregation without relying on CXL 3.x features that aren’t available, whereas the RNIC (RDMA NIC) side allows scaling to very large systems for workloads that can tolerate additional latency,” says Wheeler.
System benefits
Sankar cites two GPU platforms - one proprietary and one an open system - to highlight its chip benefits. The platforms are Nvidia’s DGX-H100 box and the open-design Grand Teton announced by Meta.
“The DGX has become a sort of fundamental commodity or a unit of AI computing,” says Shankar.
The DGX uses eight H100 GPUs, CPUs (typically two), I/O devices that link the GPUs using NVlink, and Infiniband for networking. The Meta platform has a similar specification but uses Ethernet.
Both systems have eight 400-gigabit interfaces. “That is 3.2 terabits coming out of the appliance, and inside the device, there is 3.2 terabit connected to a bunch of compute resources,” says Sankar.
The Meta platform includes layers of PCIe switches, and Open Compute Project (OCP 3.0) NICs running at 200 gigabits, going to 400 gigabits in the next generation.
The Grand Teton platform also uses eight NICs, four PCIe switches, and likely a top-of-rack switch to connect multiple systems.
Enfabrica’s vision is to enable a similarly composable [GPU] system. However, instead of eight NICs, four PCIe switches and the external top-of-rack switch, only three devices would be needed: two Enfabrica accelerated compute fabric chips and a control processor.
Enfabrica says the design would halve the power compared to the existing NICs, PCIe switches and the top-of-rack switch. “That represents 10 per cent of the rack’s power,” says Sankar.
And low-latency memory could be added to the space saved by using three chips instead of 12. Then, the eight GPUs would have tens of terabytes of memory to share whereas now each GPU has 80 gigabytes of HBM.
What next?
Enfabrica is unveiling the architecture first, and will detail its product later this year.
It is key to unveil the accelerated compute fabric concept now given how AI architectures are still nascent, says Sankar.
But to succeed, the start-up must win a sizeable data-centre customer such as a hyperscaler, says Wheeler: “That means there’s a very short list of customers, and winning one is paramount.”
The supplier must deliver high volumes from the start and guarantee supply continuity, and may also have to provide the source code to ensure that a customer can maintain the product under any circumstances.
“These are high hurdles, but Innovium proved it can be done and was rewarded with an exit at a valuation of greater than $1 billion,” says Wheeler.